Psychology, a Failed Discipline

In my previous article, The Problem is Not Plagiarism, but Cargo Cult Science, I claimed that upwards of 90% of non-STEM academic papers should be classified as Cargo Cult Science. This assertion prompted a challenge from a HackerNews commenter who said I should “Pick a field and debunk it if you can.”
To reiterate, Richard Feynman considers the main feature of Cargo Cult Science to be the following:
But there is one feature I notice that is generally missing in Cargo Cult Science. That is the idea that we all hope you have learned in studying science in school—we never explicitly say what this is, but just hope that you catch on by all the examples of scientific investigation. It is interesting, therefore, to bring it out now and speak of it explicitly. It’s a kind of scientific integrity, a principle of scientific thought that corresponds to a kind of utter honesty—a kind of leaning over backwards. For example, if you’re doing an experiment, you should report everything that you think might make it invalid—not only what you think is right about it: other causes that could possibly explain your results; and things you thought of that you’ve eliminated by some other experiment, and how they worked—to make sure the other fellow can tell they have been eliminate
I’ve selected psychology as my Cargo Cult Science field of choice primarily because it’s one of the most obviously fraught subjects and due to my own brief academic detour into this field after dropping out of engineering (a very questionable decision in hindsight).
In psychology, papers are either p-hacked garbage that doesn’t replicate or, more commonly, have no scientific value due to their methodology or subject of study. These papers aren’t necessarily “false” per se, as much as they don't produce any valuable knowledge by design, serving mainly to advance the careers of the authors through journal publications and the gathering of press and citations. I consider all these Cargo Cult Science.
While p-hacking and the replication crisis are widely acknowledged, albeit not solved, problems, I argue that these are minor compared to the four major issues that undermine psychology: reliance on surveys, disregarding indexicality, studying nouns, and using statistics.
This post will discuss the weaknesses in psychological research outside of clinical psychology. In a subsequent post, I plan to explore the problems with “mental illnesses” (especially depression) and their treatment.
Advertising
One of the most prominent paradigms in psychology, popularized by Daniel Kahneman’s seminal book “Thinking, Fast and Slow,” revolves around the concepts of biases, nudging, and priming. Kahneman, in collaboration with Amos Tversky, laid the groundwork for the field now known as behavioral economics.
This line of research studies how “irrational” people behave in various scenarios and suggests that subtle cues can be used to “nudge” or “prime” individuals toward making more “rational” decisions. It operates on the assumption that human behavior is predominantly governed by unconscious and irrational forces, a concept Kahneman refers to as System 1, which eludes our direct control.
Daniel Kahneman explains this view as follows:
When I describe priming studies to audiences, the reaction is often disbelief. This is not a surprise: System 2 believes that it is in charge and that it knows the reasons for its choices. Questions are probably cropping up in your mind as well: How is it possible for such trivial manipulations of the context to have such large effects? Do these experiments demonstrate that we are completely at the mercy of whatever primes the environment provides at any moment? Of course not. The effects of the primes are robust but not necessarily large. Among a hundred voters, only a few whose initial preferences were uncertain will vote differently about a school issue if their precinct is located in a school rather than in a church—but a few percent could tip an election.
The idea you should focus on, however, is that disbelief is not an option. The results are not made up, nor are they statistical flukes. You have no choice but to accept that the major conclusions of these studies are true.
I, like Science Banana in her post Against Automaticity, will argue that disbelief is not only an option but that it is the correct option.
The automaticity frame, where people are seen as helplessly malleable via their unconscious System 1, also infiltrated common beliefs about advertising mechanisms. Kevin Simler addresses this in his essay Ads Don’t Work That Way, where he critiques the prevalent notion that advertisements primarily work by manipulating our emotions. Traditional advertising theory suggests that ads forge positive links between a product and emotions subtly influencing our purchasing decisions over time.
However, Simler introduces an alternative, more “rational” theory he terms “cultural imprinting.” This theory posits that advertising informs consumers about the social signals they broadcast when purchasing a product:
If I'm going to bring Corona to a party or backyard barbecue, I need to feel confident that the message I intend to send (based on my own understanding of Corona's cultural image) is the message that will be received. Maybe I'm comfortable associating myself with a beach-vibes beer. But if I'm worried that everyone else has been watching different ads ("Corona: a beer for Christians"), then I'll be a lot more skittish about my purchase.
This explanation has the advantage of not only making more intuitive sense but also of treating consumers not as agents wholly governed by subconscious emotional associations.
In contrast, the typical emotional inception theory appears almost ridiculous: the idea that mere exposure to appealing imagery associated with a product will inherently foster a positive association and drive purchase decisions. Simler highlights how extraordinary the claim is:
This meme or theory about how ads work — by emotional inception — has become so ingrained, at least in my own model of the world, that it was something I always just took on faith, without ever really thinking about it. But now that I have stopped to think about it, I'm shocked at how irrational it makes us out to be. It suggests that human preferences can be changed with nothing more than a few arbitrary images. Even Pavlov's dogs weren't so easily manipulated: they actually received food after the arbitrary stimulus. If ads worked the same way — if a Coke employee approached you on the street offering you a free taste, then gave you a massage or handed you $5 — well then of course you'd learn to associate Coke with happiness.
I reference this example to highlight two critical points. First, it demonstrates that it is feasible to find a more logical and rational explanation for a phenomenon that looks “irrational” at first. Second, it reveals how after examining an alternative explanation, the widely accepted beliefs can seem very unconvincing.
Biases, Nudging, Priming
Research within the “Bias, Nudging, and Priming” paradigm typically falls into one of two categories: it either fails to replicate, or the observed effects can be more convincingly explained by rational behavior, which may appear unusual within the confines of an artificial experimental environment. Gerd Gigerenzer’s paper, The Bias Bias in Behavioral Economics, provides an in-depth analysis of the issues surrounding various biases that are said to “replicate”:
Behavioral economics began with the intention of eliminating the psychological blind spot in rational choice theory and ended up portraying psychology as the study of irrationality. In its portrayal, people have systematic cognitive biases that are not only as persistent as visual illusions but also costly in real life—meaning that governmental paternalism is called upon to steer people with the help of “nudges.” These biases have since attained the status of truisms. In contrast, I show that such a view of human nature is tainted by a “bias bias,” the tendency to spot biases even when there are none. This may occur by failing to notice when small sample statistics differ from large sample statistics, mistaking people’s random error for systematic error, or confusing intelligent inferences with logical errors. Unknown to most economists, much of psychological research reveals a different portrayal, where people appear to have largely fine-tuned intuitions about chance, frequency, and framing.
We cannot go through the whole paper, which I highly recommend reading, but we will discuss two illustrative examples:
Framing effects were said to violate “description invariance,” an “essential condition” for rationality (Tversky and Kahneman, 1986, p. S253). People were also said to lack insight: “in their stubborn appeal, framing effects resemble perceptual illusions more than computational errors” (Kahneman and Tversky, 1984, p. 343). Similarly, when a study found that experienced national security intelligence officers exhibited larger “framing biases” than did college students, this finding was interpreted as a surprising form of irrationality among the experienced officers (Reyna et al., 2014).
Consider a classical demonstration of framing. A patient suffering from a serious heart disease considers high-risk surgery and asks a doctor about its prospects. The doctor can frame the answer in two ways:
Positive Frame: Five years after surgery, 90% of patients are alive.
Negative Frame: Five years after surgery, 10% of patients are dead.
Should the patient listen to how the doctor frames the answer? Behavioral economists say no because both frames are logically equivalent (Kahneman, 2011). Nevertheless, people do listen. More are willing to agree to a medical procedure if the doctor uses positive framing (90% alive) than if negative framing is used (10% dead) (Moxey et al., 2003). Framing effects challenge the assumption of stable preferences, leading to preference reversals. Thaler and Sunstein (2008) who presented the above surgery problem, concluded that “framing works because people tend to be somewhat mindless, passive decision makers” (p. 40).
However, as Gigerenzer explains, viewing people as “mindless” is not the only way to interpret the results. The opposite is likely the case:
For the patient, the question is not about checking logical consistency but about making an informed decision. To that end, the relevant question is: Is survival higher with or without surgery? The survival rate without surgery is the reference point against which the surgery option needs to be compared. Neither “90% survival” nor “10% mortality” provides this information.
There are various reasons why information is missing and recommendations are not directly communicated. For instance, U.S. tort law encourages malpractice suits, which fuels a culture of blame in which doctors fear making explicit recommendations (Hoffman and Kanzaria, 2014). However, by framing an option, doctors can convey information about the reference point and make an implicit recommendation that intelligent listeners intuitively understand. Experiments have shown, for instance, that when the reference point was lower, that is, fewer patients survived without surgery, then 80–94% of speakers chose the “survival” frame (McKenzie and Nelson, 2003). When, by contrast, the reference point was higher, that is, more patients survived without surgery, then the “mortality” frame was chosen more frequently. Thus, by selecting a positive or negative frame, physicians can communicate their belief whether surgery has a substantial benefit compared to no surgery and make an implicit recommendation.
The same is true for the framing effect in the “Asian disease problem,” which presents a scenario where the United States faces an outbreak expected to kill 600 people. Two programs to address the disease are proposed, each described in either a positive or negative light.
Positive Frame
If Program A is adopted, 200 people will be saved.
If Program B is adopted, there is a 1/3 probability that 600 people will be saved and a 2/3 probability that no people will be saved.
Negative Frame
If Program A is adopted, 400 people will die.
If Program B is adopted, there is a 1/3 probability that nobody will die and a 2/3 probability that 600 people will die.
Tversky and Kahneman observed that people’s preferences varied with the framing: Program A was favored under positive framing, while Program B was chosen more often under negative framing. This outcome, contradicting the notion of stable preferences, “demonstrates” that people tend to avoid risk when a positive frame is presented (preferring the certain saving of 200 lives) and seek risk in the face of potential losses (opting for the chance to save all 600 lives). Tversky and Kahneman argued that since both scenarios are logically equivalent, farming should not alter people’s preferences.
But if we again assume that people make intelligent inferences about left-out information, this discrepancy is not irrational. Note that the “certain” options are both incomplete while the “risky” options include numbers for both those who will be saved and those who will die. We can include this missing information and rewrite the positive frame as:
If Program A is adopted, 200 people will be saved and 400 people will not be saved.
If Program B is adopted, there is a 1/3 probability that 600 people will be saved and a 2/3 probability that no people will be saved.
Gigerenzer notes the perhaps surprising differences when including this logically irrelevant information:
If any of the proposed explanations given—people’s susceptibility to framing errors, their risk aversion for gains and risk seeking for losses, or the value function of prospect theory—were true, this addition should not matter. But in fact, it changes the entire result. When the information was provided completely, the effect of positive versus negative frames disappeared in one study after the other (e.g. Kühberger, 1995; Kühberger and Tanner, 2010; Mandel, 2001; Tombu and Mandel, 2015). Further studies indicated that many people notice the asymmetry and infer that the incomplete option means that at least 200 people are saved because, unlike in Program B, the information for how many will not be saved is not provided (Mandel, 2014). Under this inference, Program A guarantees that 200 or more people are saved, as opposed to exactly 200. Thus, people’s judgments appear to have nothing to do with unstable preferences or with positive versus negative framing. The incompleteness of Program A alone drives the entire effect. When supplied with incomplete information, people have to make intelligent inferences. Doing so is not a bias.
Gigerenzer’s critique of other biases often follows this pattern. He shows that the standard definition of “rationality” (rational choice theory) doesn’t make sense in the complex, context-dependent reality in which people make decisions. It is therefore no wonder when people’s choices deviate from that theory, but it is not a “bias.” Gigerenzer advocates for a theory he terms “ecological rationality,” which emphasizes the role of context in human decision-making.
To illustrate this point further, we can look at another well-known example. Many experiments show people believe that a sequence like HHTH (where “H” denotes heads and “T” denotes tails) is more likely than HHHH when flipping a coin multiple times. Behavioral economists criticize this belief, arguing that all sequences are equally likely.
However, Gigerenzer shows that this is not necessarily correct. When we look at a finite sample larger than the pattern, the sequence HHTH is indeed more likely to occur than HHHH. Only when we are concerned with an infinite sample (impossible in real life) or a sample that is exactly the length of the pattern we are looking for (in this case 4) are the two patterns equally likely. The reason for this is as follows. For either of these patterns to occur we first need two heads in a row. Then, when searching for the HHHH pattern, we need a third heads. Consider the unlucky case where we flip the coin and it shows tails. We would have to start the pattern from the very beginning – looking for our first heads again. Now examine the other pattern: We are looking for HHTH, so we want tails in our third throw. The difference is that in the unlucky case of an H, we don’t need to start from the very beginning because heads can be seen as the first heads we need in our HHTH pattern. When we get unlucky, we get to start at the second heads. In contrast, when looking for the HHHH pattern, the unlucky T doesn’t help us at all and we need to look for our first heads again.
Human intuition is therefore not flawed as suggested by conventional bias research. In real-world scenarios, where infinite samples don’t exist and sample sizes don’t exactly match the pattern length, people’s intuitions about probability patterns are accurate: HHTH occurs more often than HHHH. The “mathematically correct” answer is mostly wrong in practice. Instead of calling this result a “bias” or “irrational”, we should question the artificial nature of the experiment.
For those who are unconvinced, Gigerenzer proposes the law-of-small-numbers bet:
You flip a fair coin 20 times. If this sequence contains at least one HHHH, I pay you $100. If it contains at least one HHHT, you pay me $100. If it contains neither, nobody wins.
Do not take it.
Scott Alexander To The Rescue
In his response to Banana’s critique titled “Here's Why Automaticity Is Real Actually,” Scott Alexander acknowledges the debunking of several striking findings in the field but maintains that certain “cognitive biases are real, well-replicated, and have significant explanatory value.”
I find his argument less than persuasive, particularly regarding his assertion:
[Cognitive biases] exist. They can be demonstrated in the lab. They tell us useful things about how our brains work. Some of them matter a lot, in the sense that if we weren’t prepared for them, bad things would happen.
Contrary to Scott Alexander, I hold that cognitive biases can only be “demonstrated” in a laboratory setting, offering little insight into the actual workings of our brains, have little to no explanatory value, and lack of preparedness for these “biases” does not result in negative consequences in real life.
Alexander cites hyperbolic discounting as an example of a cognitive bias that could lead to adverse outcomes if not recognized:
Hyperbolic discounting is a cognitive bias. But when it affects our everyday life, we call it by names like “impulsivity” or “procrastination”.
Hyperbolic discounting is not a bias in any meaningful sense of the term. To understand his claim, consider the Wikipedia entry for Hyperbolic discounting:
Given two similar rewards, humans show a preference for one that arrives in a more prompt timeframe. Humans are said to discount the value of the later reward, by a factor that increases with the length of the delay. In the financial world, this process is normally modeled in the form of exponential discounting, a time-consistent model of discounting. Many psychological studies have since demonstrated deviations in instinctive preference from the constant discount rate assumed in exponential discounting.Hyperbolic discounting is an alternative mathematical model that agrees more closely with these findings
What Scott calls a “bias” is the fact that people do not have a time-consistent discount rate. An example taken from Time Discounting and Time Preference: A Critical Review by Frederick, Loewenstein, and Donoghue might help:
For example, Richard Thaler (1981) asked subjects to specify the amount of money they would require in [one month/one year/ten years] to make them indifferent to receiving $15 now. The median responses [$20/$50/$100] imply an average (annual) discount rate of 345 percent over a one-month horizon, 120 percent over a one-year horizon, and 19 percent over a ten-year horizon
The term “bias” denotes the fact that even though the exponential discounting model predicts that the annual discount rate should be the same no matter the time frame, it isn’t.
A more accurate interpretation of this finding would be to acknowledge it as evidence that a well-known economic model fails to accurately predict human behavior. In other words, when humans don’t conform to your theory, search for the problem in the theory, not in the humans.
This broad pattern of calling people’s actions and choices “biased” when they do not agree with some famous mathematical theory explains much of what Gigerenzer calls “The Bias Bias.” The underlying assumption of such labeling is that deviations from theoretical models indicate “irrationality,” potentially leading to adverse outcomes. This assumption forms the basis for the argument in favor of “nudging” individuals towards certain behaviors.
However, the claim that these so-called biases lead to negative consequences is not supported by any evidence. On the contrary, as discussed, real-life scenarios often demonstrate that people’s intuitive decisions can be more “rational” than those guided by naive application of mathematical models. In many cases, these intuitive heuristics take into account a surprising amount of complexity of the real world that is difficult to model mathematically.
Scott Alexander’s selection of cognitive biases that he argues are well-replicated serve as a further example of this phenomenon. Remember, these are the best he could come up with:
The conjunction fallacy is not only well-replicated, but easy to viscerally notice in your own reasoning when you look at classic examples. I think it’s mostly survived critiques by Gigerenzer et al, with replications showing it happens even among smart people, even when there’s money on the line, etc. But even the Gigerenzer critique was that it’s artificial and has no real-world relevance, not that it doesn’t exist.Loss aversion has survived many replication attempts and can also be viscerally appreciated. The most intelligent critiques, like Gal & Rucker’s, argue that it’s an epiphenomenon of other cognitive biases, not that it doesn’t exist or doesn’t replicate.The big prospect theory replication paper concluded that “the empirical foundations for prospect theory replicate beyond any reasonable thresholds.”
The conjunction fallacy is obviously a consequence of the artificial lab setting where subjects make informed guesses that are often correct in the real world but look foolish in the experiment. I doubt even Scott would claim it has any real-world applications. Moreover, as is often the case, the effect vanishes when expressed in frequencies as opposed to probabilities or when participants are forced to slow down:
In one experiment the question of the Linda problem was reformulated as follows:
There are 100 persons who fit the description above (that is, Linda's). How many of them are:Bank tellers? __ of 100Bank tellers and active in the feminist movement? __ of 100
Whereas previously 85% of participants gave the wrong answer (bank teller and active in the feminist movement), in experiments done with this questioning none of the participants gave a wrong answer.
The other two points on Scott’s list are almost identical as prospect theory relies heavily on loss aversion. Prospect theory acknowledges that people’s choices can deviate from traditional expected utility theory – such as valuing losses more heavily than equivalent gains – but it does not offer an underlying reason for these preferences. It merely labels these deviations “biases.”
In the case of loss aversion, I have to side with Nassim Taleb, who wrote in Skin in The Game:
The he flaw in psychology papers is to believe that the subject doesn’t take any other tail risks anywhere outside the experiment and will never take tail risks again. The idea of “loss aversion” have not been thought through properly –it is not measurable the way it has been measured (if at all mesasurable). Say you ask a subject how much he would pay to insure a 1% probability of losing $100. You are trying to figure out how much he is “overpaying” for “risk aversion” or something even more stupid, “loss aversion”. But you cannot possibly ignore all the other present and future financial risks he will be taking. You need to figure out other risks in the real world: if he has a car outside that can be scratched, if he has a financial portfolio that can lose money, if he has a bakery that may risk a fine, if he has a child in college who may cost unexpectedly more, if he can be laid off. All these risks add up and the attitude of the subject reflects them all. Ruin is indivisible and invariant to the source of randomness that may cause it.
More formally, loss aversion may be rational in non-ergodic systems.
As I explained in An Introduction to Ergodicity four years ago, an ergodic system is technically defined as a system that has the same behavior averaged over time as it has averaged over the space of all the system’s states.
More intuitively, it’s the difference between rolling a dice and Russian roulette. When rolling a dice, it doesn’t matter whether one person rolls a dice 100 times or if we let 100 people roll one dice each, making it ergodic. In contrast, Russian roulette is non-ergodic. If we let one person play Russian Roulette 100 times (assuming the chance of death is, say, 1/6), he will certainly die (1-(5/6)^100 = 0.9999999879), but if we let 100 people Russian roulette once, we only expect 1/6 x 100 = 16.6666 to die.
The concept of ergodicity is crucial to understanding phenomena like the Gambler's Ruin, which states that a gambler, even when making bets with positive expected value, will eventually go bankrupt. This outcome arises because, in a non-ergodic system, the effect of accumulating losses over time can lead to a point of no return. In The Gambler's Ruin, this point is bankruptcy. Similarly, in Russian roulette, it's death.
Taleb’s point above is that in a world where the risk of bankruptcy exists (non-ergodic), it is rational for people not to value losses equally as gains. For instance, in experiments where subjects are reluctant to take a fair coin toss bet with a potential gain of $1200 or a loss of $1000 (an expected value of $200), their hesitance reflects an understanding that multiple losses in similar bets could lead to financial ruin in real life. The “mistake” participants make is to not separate the hypothetical nature of the experiment (where going bankrupt doesn’t matter) from their real life and financial situations.
From this perspective, behavior that might seem irrational or overly cautious in an isolated laboratory setting (especially with the use of play money) can be entirely rational in the context of real-world uncertainties. In situations where ergodicity does not apply, “loss aversion” is not so much a cognitive bias as it is a practical strategy for not accidentally going bust.
Just like “Hyperbolic discounting”, “loss aversion” is mainly evidence of a flawed mainstream economic model, not a “bias” requiring correction. In these instances, people's choices often display a level of “rationality” that accounts for complex circumstances, which mathematical models too easily overlook.
Scott Alexander cites other examples, such as the impact of default tipping options in services like Uber, as evidence for the reality of “nudging” and “priming.” It is obviously correct that the default tipping options influence how much customers tip. In fact, it is so obvious that it’s almost laughable as Scott himself admits:
But you shouldn’t need to hear that scientists have replicated this. If you’ve ever taken a taxi, you should have a visceral sense of how yeah, you mostly just click a tip option somewhere in the middle, or maybe the last option if the driver was really good and you’re feeling generous.
This form of “nudging” is not at all similar to the surprising “How is it possible for such trivial manipulations of the context to have such large effects?” that Kahneman is famous for. I may similarly observe that what’s in my fridge “nudges” my decision of what I will eat later today. Scott seems to believe that this is evidence in favor of automaticity.
Placebos
When discussing the placebo effect, it's important to distinguish between two commonly conflated phenomena. The first is the role of placebos in clinical trials. In this context, a placebo serves to filter out noise, the self-healing of the body, regression to the mean, and other effects that shouldn’t be attributed to the medication. The placebo is explicitly chosen because it has no therapeutic effect, simulating “doing nothing.” In this sense, the “placebo effect” is not located in the pill, which does nothing, but is a consequence of spontaneous recovery and other effects that are classified as noise in clinical trials. This version of the placebo effect – reversion to the mean – is obviously real and not strange at all.
However, the popular understanding of the placebo effect differs. It refers to the belief that a person can experience tangible health benefits from taking a “placebo” (a sugar pill), simply due to the belief of receiving treatment. Moreover, these benefits are said to go beyond doing nothing. The effect, in this case, is located in the pill itself. This interpretation has been extended to suggest that, “A placebo can work even when you know it’s a placebo” a claim that leads one to question the sanity of everyone involved.
Studies comparing the effects of a placebo (a sugar pill) to doing nothing frequently show that the mystical “placebo effect” is non-existent. Even proponents of the mystical placebo effect cautiously note its limitations:
placebos won’t work for every medical situation—for example, they can’t lower cholesterol or cure cancer. But they can work for conditions that are defined by “self-observation” symptoms like pain, nausea, or fatigue.
The mystical placebo effect is “real” for conditions that can only be observed subjectively. A rather curious effect indeed. Even then, the effect probably doesn’t exist.
I posit that for the same category of conditions, thinking “I will get better in 10 min” also “helps.” It’s important to note that helping, in this case, means people answer a survey differently next time, which brings us to our next topic.
Surveys
Many findings in psychology rely on surveys, often because they are the most accessible, cost-effective, or the only possible method for collecting certain types of data. However, like our friendly Banana, I consider surveys to be bullshit:
It is not the case that knowledge can never be obtained in this manner. But the idea that there exists some survey, and some survey conditions, that might plausibly produce the knowledge claimed, tends to lead to a mental process of filling in the blanks, of giving the benefit of the doubt to surveys in the ordinary case. But, I think, the ordinary survey, in its ordinary conditions, is of no evidentiary value for any important claim. Just because there exist rare conditions where survey responses tightly map to some condition measurable in other ways does not mean that the vast majority of surveys have any value.
Banana points out that there exists no historical instrument similar to that of the survey. Like statistics, which we will discuss later, surveys are a modern invention. Moreover, from a legal perspective, surveys can be classified as hearsay. Unlike a direct witness, who can be cross-examined to establish the veracity of his claims, a survey-taker can not be questioned. There exists no way to establish the credibility and accuracy of the claims. We don’t have the opportunity to probe deeper, to ask follow-up questions, or to even ensure that the respondent has correctly understood the question in the intended manner. This limitation is significant because, as we have seen above in the Asian Disease example, people make all sorts of assumptions beyond what the scientists intended. What makes this flaw potentially fatal is that we don’t notice when something goes wrong:
in the case of surveys, even if all assumptions fail, if all the pieces of the machine fail to function, data is still produced. There is no collapse or apparent failure of the machinery. But the data produced are meaningless—perhaps unbeknownst to the audience, or even to the investigators.
Banana identifies four critical components necessary for a survey to yield meaningful data: attention, sincerity, motivation, and comprehension.
She writes about attention:
In order for the survey to be meaningful, the subjects must be paying attention to the items. This is the first indication that the relationship between survey giver and survey taker is an adversarial one. The vast majority of surveys are conducted online, often by respondents who are paid for their time. (Just to give you an idea, I happened to see figures in recent publications of fifty cents for a ten-minute task and $1.65 for fifteen minutes.)
This adversarial relationship is likely part of the reason survey-takers are not always sincere. Banana attributes the “lizardman constant” (a percentage of respondents who agree that the world is run by lizardmen), and the findings that gay teens are much more likely to be pregnant, to this lack of sincerity. Respondents may simply want to have fun and give ridiculous answers, especially since they are anonym, instead of sincerely answering all questions.
Even if the survey-takers are attentive and sincere, their motivation is not clear:
A related adversarial motivation is making a point. In the normal course of conversation, in ordinary language use, one forms opinions about why the speaker is saying what she is saying, and prepares a reply based as much on this as on the words actually said. In surveys, survey takers may form an opinion about the hypothesis the instrument is investigating, and conform his answers to what he thinks is the right answer. It’s a bit subtle, but it’s easy to see in the communicative form of twitter polls. When you see a poll, and your true answer doesn’t make your point as well as another answer, do you answer truthfully or try to make a point? What do you think all the other survey respondents are doing? This is not cheating except in a vary narrow sense. This is ordinary language use—making guesses about the reasons underlying a communication, and communicating back with that information in mind. It’s the survey form that’s artificial, offered as if it can preclude this kind of communication. And even when a survey manages to hide its true hypothesis, survey takers still may be guessing other hypotheses, and responding based on factors other than their own innocent truths.
Last, we come to the most obvious problem: comprehension. Unfortunately, even when avoiding complex terms, comprehension may often be tricky:
Consider another survey question, from the General Social Survey:Taken all together, how would you say things are these days—would you say that you are very happy, pretty happy, or not too happy?
No one can accuse this of using big words (although my friend points out that “not too happy,” despite its colloquial meaning, is exactly as happy as you’d want to be). But in its simplicity, it exemplifies the complexity of the phenomenon of comprehension.
Consider what comprehension means here. It presumes first that the authors of the survey have encoded a meaning in the words, a meaning that the words will convey to the survey takers. More importantly, it presumes that this corresponds to “the real meaning” of the words—a meaning shared by the audience of the survey’s claims. What would the “real meaning” be in this very simple case? How are things these days? Are you very happy, pretty happy, or not too happy? What informs your choice? Would you have answered the same a month or a year ago? Fifteen minutes ago? How does your “pretty happy” compare with another person’s “pretty happy”? Happy compared to what? How would you predict that your family members would answer? Do they put a good face on things, or do they enjoy complaining? Would their answers correspond to how happy you think they really are? What about people from cultures you’re not familiar with? This is a three-point scale. Would you be able to notice a quarter of a point difference? What would that mean?
Now consider this graph:
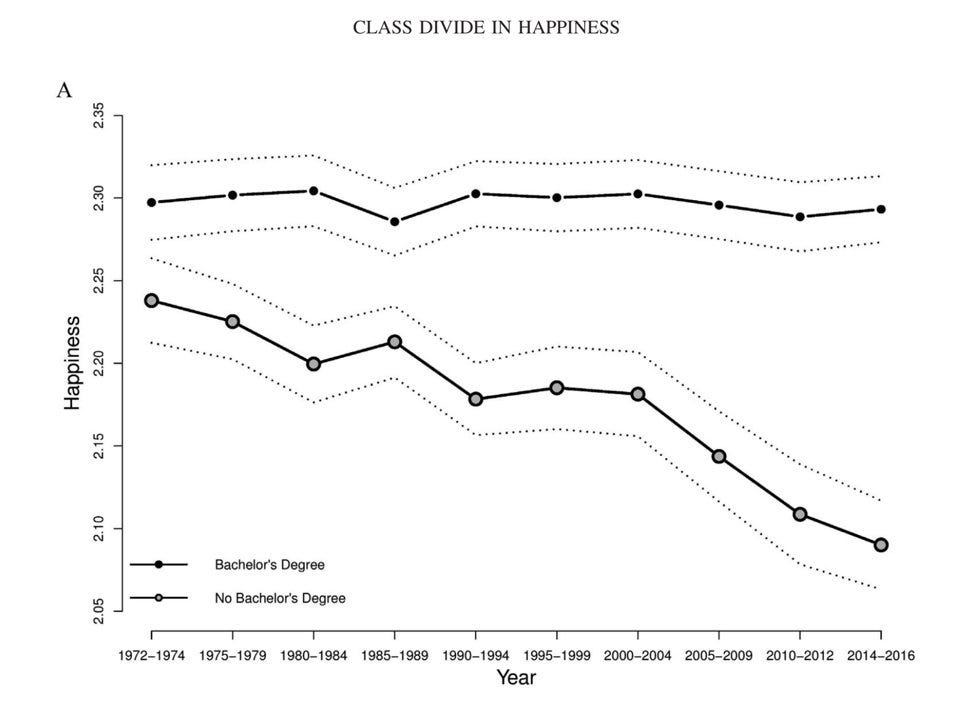
Imagine the hypothetical headlines one could base upon this survey such as “The Class Divide in Happiness is Growing!”, “Inequality in Happiness on the Rise!”, or “Higher Education Leads to Happier Lives!”
Now think about what it would take to uncover the fact that such a headline was based on a bullshit survey. One would need to read the article. Then, one would need to find the study the article is based on and read not only the abstract but the whole paper. Finally, one would have to take a look at the instrument they used to measure happiness which may be found in another paper. Nobody besides weird internet autists does that, which is why surveys are so popular.
Indexicality
Surveys are the most popular tool for creating non-indexical knowledge. In short, indexical knowledge is knowledge that is dependent on or embedded in a particular context. The opposite is objective, universal, or global knowledge.
Science Banana again:
Science has celebrated many victories in wresting objective knowledge from indexical observations, but these victories are rare, and are the product of concerted group activity backstage, rather than a natural consequence of scientific ritual. Overconfidence in the global word game, especially in social sciences, threatens the production and appreciation of the genuine kind of indexical knowledge that humans are geniuses at producing and using. The framing of “cognitive bias” privileges the global knowledge game at the expense of a richly situated rationality (what Gigerenzer and others call “ecological rationality”).
The preference for global as opposed to indexical knowledge in the social sciences can be understood as a part of the famous physics envy. The creation of universal knowledge that holds under basically all conditions is something physicists have been celebrated and admired for. Unfortunately, psychology is not well situated to create this kind of knowledge.
By trying to remove indexicality to create global knowledge, researchers created the flawed “bias” field we discussed above: Choices that are “rational” when considered in context become “irrational” when researchers try to remove that context.
Banana demonstrates this problem using the “behaviorally-specific questions” that are used in the National Intimate Partner and Sexual Violence Survey (2012) by the Center for Disease Control:

This certainly seems like an improvement from the “happiness” survey. Here, at least, we are working with real behavior, not some vague subjective unmeasurable state. Based on “behaviorally-specific” surveys, the CDC concludes:
Physical violence by an intimate partner was experienced by almost a third of women (32.4%) and more than a quarter of men (28.3%) in their lifetime. State estimates ranged from 25.4% to 42.1% (all states) for women and 17.8% to 36.1% (all states) for men.
But we should by now have learned to be wary of non-indexical knowledge in the social sciences. When Amy Lehrner and Nicole Allen investigated the validity of the behaviorally-focused CTS in “Construct validity of the Conflict Tactics Scales: A mixed-method investigation of women’s intimate partner violence” the result was quite surprising:
Descriptions of play fighting included behaviors coded as severe assault by the CTS, such as kicking, punching, or resulting in injury to self or partner. An exemplar of this pattern is participant 106 (level 4), who endorsed significant frequency and severity of violence on the CTS, including items such as throwing something, twisting arm or hair, pushing, shoving, grabbing, slapping and two instances of having had an injury for herself and her boyfriend. When asked about times when arguments or fights have ever “gotten physical,” she replied:
P: Honestly, not when we’re fighting have we ever been physical. I mean when we’re joking around and you know, things like that? We like to just play around and like pretend to beat each other up. But it’s not anything that would really inflict pain on each other. And if it is, it’s very minor and it’s accidental. But…
Q: Not in the context of like an argument or a conflict?
P: No. I honestly cannot remember a single time where we were fighting and it had gotten physical. Usually if anything we’re on the phone or we are 5 feet away from each other.
When questioned more directly about her CTS endorsements she responded, “I think I might have been thinking in context of playing sort of thing. . . it probably, I thought it was in the context of just at all?. . . And when we are like at all, you know, physical like that it’s just like all in fun.” When asked for examples she reported:
A: Well I’ll either just like go up to him – “let’s fight” or something – and then I’ll just like you know lightly punch him or something like that. And then you know he would like pick me up and throw me on the couch, and like start tickling me. Usually that’s what ends up stopping it is that he’ll just keep tickling me until I can’t breathe anymore. But I mean that’s pretty much it.
Q: And so you’ll get to that point where you’re trying to really overpower him and see if you can do it, and you never can?
A: Yeah. Usually the only thing I can do is like pinch him or something? I pull his hair and he’ll stop tickling me. But that’s about it.
Q: So when are the times where you’d be in the mood to say, “hey let’s fight?”
A: I don’t know, a lot of times when I’m at home, I get bored and there’s really not a lot to do in my town. So watching TV and movies gets kind of old. So we’re just you know, something to do? Like kind of like a brother/sister type of thing, where you just have nothing else to do so let’s beat up on each other kind of…
It turns out that close to 20% of the participants categorized as violent by the CTS described this type of non-serious “fun-violence.” Needless to say, generally nobody bothers to check whether the answers of survey participants actually mean what researchers think they mean.
Moreover, there exists a telephone game where often highly indexical findings get increasingly more abstracted every time they are cited, eventually reaching the form of global knowledge. Banana demonstrates this in her examination of the widely publicized fact that “Victims leave and return to a relationship an average of seven times before they leave for good.” At the end of Banana’s long and impressive investigation, she discovers the likely origins of this fact:
I tracked down what seems to be one of the only existing copies of Hilberman & Munson, and here is The Fact in its context, in a section late in the short paper called “Treatment Considerations”:The work with these sixty women has been without benefit of protection or shelter. It is slow, frustrating, and intensely anxiety-provoking, with the knowledge that a client’s self-assertion could prove fatal. It is helpful to keep in focus the following two realities. First, the client’s progress may seem small or inconsequential, for example, when a wife asserts her right to attend church. For the middle-aged woman who has been battered and isolated for twenty years however, this may be a monumental step forward. Second, it may take an average of four or five separations before the last hope for changes within the marriage ends and a decisive separation occurs. The clinician can expect a series of stormy trial separations and should not view this as a treatment “failure.” The battered woman is well aware of what she should or ought to do, and if she feels she has disappointed or failed the clinician, she will be reluctant to return to treatment in the future. The clinician’s insight and understanding will make it possible for her to resume the psychotherapeutic work when she is ready to do so.
(Emphasis mine.)
Again, note that this is not presented as statistical information about a population, but in a very qualified way. It “may take” an average of four or five separations – or it may not. The paper gives no indication that this version of The Fact is based on data collected from the study, rather than the author’s impression.
In addition to the odd temporality of the global knowledge game, it presents us with an odd sense of identity. Hilberman & Munson are cited for The Fact in general, without regard to their very unusual study population. They were studying a sort of Silent Hill town, a rural and very poor place. In a twelve month period, they say, “half of all women referred by the medical staff of a rural health clinic for psychiatric evaluation were found to be victims of marital violence.” That is quite a study population! But in the world of the global knowledge game, “people” are “people.” A statistic based on an impression of sixty women living a very particular local nightmare in the 1970s is laundered into a fact about women and domestic violence in general.
The Fact will obviously be cited until the end of times regardless of its validity mainly because it looks like the type of knowledge we come to expect.
A more formal version of the indexicality problem was articulated by Tal Yarkoni in his paper The Generalizability Crisis. He shows that psychologists fail to “operationalize verbal hypotheses in a way that respects researchers’ actual generalization intentions.” In short, psychologists generalize in ways, and to an extent, they are statistically speaking not allowed to.
Statistics and Epistemology
After scientists gather data with the help of a survey, the next step typically involves using statistical methods to extract knowledge from this data (removing any shred of indexicality). Here we run into more problems. First, the proficiency in statistics among psychologists is questionable at best, which is part of the reason for the aforementioned Generalizability Ciris. However, as Adam Mastroianni notes, pointing this out is a far too common critique:
In fact, one of psychologists' favorite pastimes is to complain about how other psychologists don't know how to do statistics. “It's too easy for naughty researchers to juice their stats, so we should lower the threshold of statistical significance from p = .05 to p = .005!” “Actually, we use these new statistics instead!” “In fact, we should ban p-values entirely!”
The core issue with statistical analysis in research, even when applied correctly, is that it’s not a great way to discover valuable knowledge. It is, however, a great way to write a lot of papers. Statistical analysis, like a survey, always produces a result.
Adam notes that the use of statistics is a recent phenomenon:
Modern stats only started popping off in the late 1800s and early 1900s, which is when we got familiar and now-indispensable concepts like correlation, standard deviation, and regression.
The p-value itself didn't get popular until the 1920s, thanks in part to a paper published pseudonymously by the head brewer at Guinness (yes, the beer company). So the whole ritual of “run study, apply statistical test, report significance” is only about 100 years old, and the people who invented it were probably drunk.
He outlines three primary practices employed by scientists prior to the advent of statistics: (1) They focused on identifying large-scale effects, as their methods were not refined enough to detect subtle ones; (2) They concentrated on exploring phenomena that were visibly apparent and undeniably occurring, yet lacked clear explanations; (3) They formulated bold, testable hypotheses about the functioning of the world.
The introduction of modern statistical techniques changed their approach because it allowed them to study tiny effects that may not actually exist. Researchers can then search for all the scenarios where an effect appears or disappears, creating “a perpetual motion machine powered entirely by an inexhaustible supply of p-values.”
Adam mentions the famous flag “priming” experiment as an example:
In 2008, researchers showed a random sample of participants a tiny picture of an American flag and found that people “primed” with the flag were more likely to vote for John McCain for president two weeks later, and had less positive attitudes toward Barack Obama's job performance eight months after that. In 2020, the same researchers published another paper where they can't find any effect of flag priming anymore, and wonder whether the effect has declined over time or never existed at all.
The reaction was a call for better statistics:
This “flag priming” study became one of the poster children for the replication crisis, and the overwhelming reaction is now, “People should use statistics correctly!” But that misses the point: studies like only exist because of statistics. In this case—The effect is not ginormous. In fact, it's so tiny—if it exists at all—that you can only see it with the aid of stats.It's not self-evident. It's not like people sometimes see an American flag and go “I must go vote for a Republican right away!” and hurry off to their nearest precinct. You would only go looking for a wobbly, artificial phenomenon like this when you have statistical tools for finding it.It doesn't have a gutsy, falsifiable hypothesis behind it. If you run another flag priming study and fail to find an effect, you don't have to eat your hat. You can just say, “Well of course there's a lot of noise and it's hard to find the signal. Maybe it's the wrong context, or the wrong group of people, or maybe flags mean something different now.”
Adam concludes correctly that the real lesson should be to stop doing these kinds of studies. They produce nothing of value because their intent is not to explain anything but to publish a surprising “result” that gathers attention.
This is not a new critique. Paul E. Meehl described a similar problem in 1978 :
Theories in “soft” areas of psychology lack the cumulative character of scientific knowledge. They tend neither to be refuted nor corroborated, but instead merely fade away as people lose interest. Even though intrinsic subject matter difficulties (20 listed) contribute to this, the excessive reliance on significance testing is partly responsible, being a poor way of doing science.
More formally, psychology suffers from an epistemological flaw. David Deutsch addresses this fundamental issue with “explanationless” sciences in The Beginning of Infinity:
In explanationless science, one may acknowledge that actual happiness and the proxy one is measuring are not necessarily equal. But one nevertheless calls the proxy ‘happiness’ and moves on. One chooses a large number of people, ostensibly at random (though in real life one is restricted to small minorities such as university students, in a particular country, seeking additional income), and one excludes those who have detectable extrinsic reasons for happiness or unhappiness (such as recent lottery wins or bereavement). So one’s subjects are just ‘typical people’ – though in fact one cannot tell whether they are statistically representative without an explanatory theory. Next, one defines the ‘heritability’ of a trait as its degree of statistical correlation with how genetically related the people are. Again, that is a non-explanatory definition: according to it, whether one was a slave or not was once a highly ‘heritable’ trait in America: it ran in families. More generally, one acknowledges that statistical correlations do not imply anything about what causes what. But one adds the inductivist equivocation that ‘they can be suggestive, though.
This methodological shortcoming is evident in the above-discussed flag priming study. One can easily see how the same methodology could produce Deutsch’s hypothetical “Slavery is heritable” paper.
This epistemological gap leads to the most concerning and amusing aspect of the replication crisis: the general indifference toward the falsification of any specific paper.
Adam writes in I’m so sorry for psychology’s loss, whatever it is:
In 2015, a big team of researchers tried to redo 100 psychology studies, and about 60% failed to replicate.This finding made big waves and headlines, and it's already been cited nearly 8,000 times.
But the next time someone brings it up, ask them to name as many of the 100 studies as they can. My bet is they top out at zero. I'm basically at zero myself, and I've written about that study at length. (I asked a few of my colleagues in case I'm just uniquely stupid, and their answers were: 0, 0, 0, 0, 1, and 3.)
Isn’t that a curious fact? While there is a concern about the replication crisis in the abstract, there’s a marked disinterest in the replication outcomes of specific studies. Contrast this with physics: if a review of 100 renowned experiments revealed only 50 of them replicate, everyone would immediately want to know which experiments were successfully replicated. This is because in physics, established theories could be challenged depending on experimental outcomes. However, since psychology largely consists of a mountain of correlations, biases, and survey data, rather than coherent theories and explanations, nobody cares if some of that turns out to be false. There is nothing to falsify.
Theories “tend neither to be refuted nor corroborated, but instead merely fade away as people lose interest” mainly because they are not explanatory theories to begin with.
Studying Nouns
Adam identifies three proto-paradigms. The first two - “biases” and “priming” we have already discussed. Third is a proto-paradigm he calls “studying nouns.”
Adam explains that in this “pick a noun and study it” approach, researchers select an abstract concept and gather data on it. For instance, extensive research might be conducted on a concept like “leadership,” exploring various questions such as the value people place on leadership, its predictive power for company performance, cultural variations in leadership styles, and its correlation with other abstract ideas like ideology or creativity.
This approach suffers from three flaws:
First, there's this whole tricky issue about fictions being fictional. You can't study leadership directly, so you have to turn it into something nonfictional that you can measure. “Studying leadership,” then, actually means studying responses to the Oregon Leadership Inventory or whatever, or counting the “leader-like” words that people use, or correlating the ratings that people give to their bosses. You could be watching little league soccer teams, or corporate board meetings, or subway conductors, and all this can get crammed under the heading of “studying leadership,” even though it’s possible that none of it has anything to do with anything else. This is about as useful as a grocery store that has one big section labeled “ITEMS.”
Second, “pick a noun” always gives you results. How much do people value leadership? More than zero, no doubt. Can leadership predict a company's performance? With your infinite freedom to define and measure leadership however you want, it sure can. Are there cross-cultural differences in leadership? Keep looking and you'll find some eventually.
And third, “pick a noun” never tells you to stop. How many leadership studies are required before we understand leadership? 500? 1,000? 1 million? How would we know? There are always more questions we can ask about leadership, more fictions we can correlate it with, more ways we can define it. It's a perpetual motion machine, a science game that never ends.
These latter two issues may sound familiar by now. These are not bugs, but features of all successful paradigms in academic psychology. Exploring an inexhaustible, unfalsifiable, and explanationless paradigm is the epitome of junk science, yet it serves as the most effective strategy for forging a successful academic career.
The Innocent Scientist
Having extensively examined the methodological and epistemological problems of psychology, it is now time to shift our attention to the scientists themselves. In her analysis of the prerequisites for a credible survey, Banana begins with the premise of “Given innocent scientists, ...” Here at Unfashionable, nothing could be further from our mind.
The general public often places undue trust in academic institutions, largely due to an idealized perception of scientists. However, in the 21st century, many academics in psychology are predominantly career-oriented. Their primary goal is to publish extensively in prestigious, high-impact journals, gather numerous citations, and, if possible, gain media attention for their surprising findings, allowing them to publish books and give TED talks. Since advancement in academic careers is facilitated more by forming alliances with colleagues than by critically evaluating their work, the peer-review process has devolved into a superficial ritual.
While there are certainly scientists, including (presumably) some in psychology, who prioritize truth and ethical research practices over career advancement, they quickly find themselves outcompeted by those who engage in questionable practices like p-hacking. This selection pressure explains the prevalence of data fraud at the highest level of academia. Some recent instances may help illustrate this point: The president of Stanford resigned following revelations of data fabrication; Francesca Gino, a renowned behavioral psychologist, also seems to have faked her data; Gregg Semenza, a 2019 Nobel Prize recipient in medicine, falsified and manipulated images in at least 20 or so papers. In addition, we recently witnessed the plagiarism scandals surrounding ex-Harvard president Claudine Gay and Neri Oxman that I wrote about in The Problem is Not Plagiarism, but Cargo Cult Science.
An optimist might argue that data fabrication and plagiarism, though regrettable, are not representative of the norm. They are correct - but what then is the norm? How much integrity does the average academic have? How do they conduct their research? Do they have Feynman’s “utter honesty—a kind of leaning over backwards”?
To address these questions, we cannot solely depend on leaks, as they can be dismissed as exceptions. Instead, we need a forthright admission from a social scientist about his research methodologies. Such transparency is understandably rare, as few would publicly confess to practices that fall short of the scientific standards expected by the public.
Luckily, there is the case of Brian Wansink, a renowned behavioral scientist specializing in consumer psychology. He was on top of his field appearing regularly on television and on various podcasts. In 2016, Wansink published a candid blog post entitled “The Grad Student Who Never Said 'No'", which provides an unvarnished look at his research methods. This incredible post merits full reproduction:
A PhD student from a Turkish university called to interview to be a visiting scholar for 6 months. Her dissertation was on a topic that was only indirectly related to our Lab's mission, but she really wanted to come and we had the room, so I said "Yes."
When she arrived, I gave her a data set of a self-funded, failed study which had null results (it was a one month study in an all-you-can-eat Italian restaurant buffet where we had charged some people ½ as much as others). I said, "This cost us a lot of time and our own money to collect. There's got to be something here we can salvage because it's a cool (rich & unique) data set." I had three ideas for potential Plan B, C, & D directions (since Plan A had failed). I told her what the analyses should be and what the tables should look like. I then asked her if she wanted to do them.
Every day she came back with puzzling new results, and every day we would scratch our heads, ask "Why," and come up with another way to reanalyze the data with yet another set of plausible hypotheses. Eventually we started discovering solutions that held up regardless of how we pressure-tested them. I outlined the first paper, and she wrote it up, and every day for a month I told her how to rewrite it and she did. This happened with a second paper, and then a third paper (which was one that was based on her own discovery while digging through the data).
At about this same time, I had a second data set that I thought was really cool that I had offered up to one of my paid post-docs (again, the woman from Turkey was an unpaid visitor). In the same way this same post-doc had originally declined to analyze the buffet data because they weren't sure where it would be published, they also declined this second data set. They said it would have been a "side project" for them they didn't have the personal time to do it. Boundaries. I get it.
Six months after arriving, the Turkish woman had one paper accepted, two papers with revision requests, and two others that were submitted (and were eventually accepted -- see below). In comparison, the post-doc left after a year (and also left academia) with 1/4 as much published (per month) as the Turkish woman. I think the person was also resentful of the Turkish woman.
Balance and time management has its place, but sometimes it's best to "Make hay while the sun shines."
About the third time a mentor hears a person say "No" to a research opportunity, a productive mentor will almost instantly give it to a second researcher -- along with the next opportunity. This second researcher might be less experienced, less well trained, from a lessor school, or from a lessor background, but at least they don't waste time by saying "No" or "I'll think about it." They unhesitatingly say "Yes" -- even if they are not exactly sure how they'll do it.
Facebook, Twitter, Game of Thrones, Starbucks, spinning class . . . time management is tough when there's so many other shiny alternatives that are more inviting than writing the background section or doing the analyses for a paper.
Yet most of us will never remember what we read or posted on Twitter or Facebook yesterday. In the meantime, this Turkish woman's resume will always have the five papers below.
This, ladies and gentlemen, is how academic research is conducted.
Only bad scientists get disgruntled by a “failed study which had null results.” In contrast, successful scientists are familiar with all the neat little tricks and clever strategies to salvage a study, allowing them to produce at least a paper or two from it.
Some commenters were quite surprised by Brian’s creative research methods, writing:
You pushing an unpaid PhD-student into salami slicing null-results into 5 p-hacked papers and you shame a paid postdoc for saying 'no' to doing the same.
Because more worthless, p-hacked publications = obviously better....? The quantity of publications is the key indicator of an academic's value to you?
I really hope this story is a joke. If not, your behaviour is one of the biggest causes of the proliferation of junk science in psychology and you are the one who should be shamed, not the postdoc.
Brian responded politely and a little confused:
Hi Robin,
I understand the good points you make. There isn't always a quantity and quality trade-off, but it's just really important to make hay while the sun shines. If a person doesn't want to one, they need to do the other. Unfair as it is, academia is really impatient.
Sincerely,
Brian
As Omar so memorably put it in The Wire: “It's all in the Game yo.”
Following a barrage of critical comments to his original post, Brian published an addendum that managed to worsen the situation while making it even more amusing:
Addendum I
Good discussion on this post. Here are two key clarifications to make about data analysis and about the stressed-out workloads of post-docs.
P-hacking and MTurk-iterating isn’t helpful to science, and it’s one of the reasons our lab seldom cites on-line studies. However, P-hacking shouldn’t be confused with deep data dives – with figuring out why our results don’t look as perfect as we want.
With field studies, hypotheses usually don’t “come out” on the first data run. But instead of dropping the study, a person contributes more to science by figuring out when the hypo worked and when it didn’t. This is Plan B. Perhaps your hypo worked during lunches but not dinners, or with small groups but not large groups. You don’t change your hypothesis, but you figure out where it worked and where it didn’t. Cool data contains cool discoveries. If a pilot study didn’t precede the field study, a lab study can follow -- either we do it or someone else does.
About Post-doc workloads. Academia is impatient for publications. It’s the reason why most professors don’t get tenure at their first school (I didn’t get it until my 3rd school). For Post-docs, publishing is make-or-break – it determines whether they stay in academia or they struggle in academia. Metaphorically, if they can’t publish enough to push past the academic gravitational pull as a post-doc, they’ll have to unfairly fight gravity until they find the right fit. Some post-docs are willin to make huge sacrifices for productivity because they think it's probably their last chance. For many others, these sacrifices aren’t worth it.
What follows is a tale of two young researchers.
“Either we do it or someone else does.” He is correct, of course.
He then had to publish a second addendum because some flaws in his papers were discovered. I encourage the curious reader to read all of it, including the many angry comments and his confused but polite responses.
For those puzzled by why this prominent professor openly admitted to modifying his hypotheses post-experiment and cutting up data to achieve “significant” results (the definition of p-hacked junk science), I offer the famous line from The Big Short: They are not confessing, they are bragging!
More accurately, he didn’t recognize that he was disclosing anything improper or contentious. He knows that these practices are standard in psychology research. He is simply outlining the methods he and all his colleagues use to obtain their results and what it takes to be a successful academic. His intent is to be helpful, which explains his bewilderment at the backlash.
To further illustrate this point, take a look at this email he sent to the same PhD student, which merits being printed out and framed:

“Work hard, squeeze some blood out of this rock” perfectly summarizes the state of research in psychology. I have nothing to add.
Zombie Fields
Looking at the evidence I presented above, it becomes obvious that there exist entire fields that are fake. I call these zombie fields. Zombie fields are completely devoided of any scientific value and can’t be brought back to life. Additionally, their zombie-like nature is obvious to anyone who is looking. Nonetheless, these fields – e.g., social priming – are still being worked on and funded.
Zombie fields are more prevalent than one might initially assume. While writing this post, I encountered a striking instance of this phenomenon outside social sciences: the case of renowned stem cell researcher Dr. Piero Anversa at Harvard Medical School. Dr. Anversa gained prominence in 2001 for his groundbreaking research suggesting that adult stem cells possessed abilities to regenerate hearts, potentially offering cures for heart disease. He was a rockstar in his field, being celebrated as a “research pioneer” by the American Heart Association. However, starting in 2011, scientists became suspicious because his results failed to replicate.
As reported by Reuters, a nearly six-year investigation by Brigham and Harvard culminated in a brief statement disclosing the discovery of “falsified and/or fabricated data” in 31 of Anversa's publications. In April 2017, the U.S. Justice Department, in a separate civil settlement with Brigham, found that Anversa's laboratory had engaged in data and image fabrication to secure government grants, along with “reckless or deliberately misleading record-keeping.”
What is remarkable is that this entirely fake research field continues to be funded. Out of the total funding, over $249 million – roughly 43% – has been allocated since March 2013. This was after federal authorities had been alerted to the allegations of fabrication against Anversa.
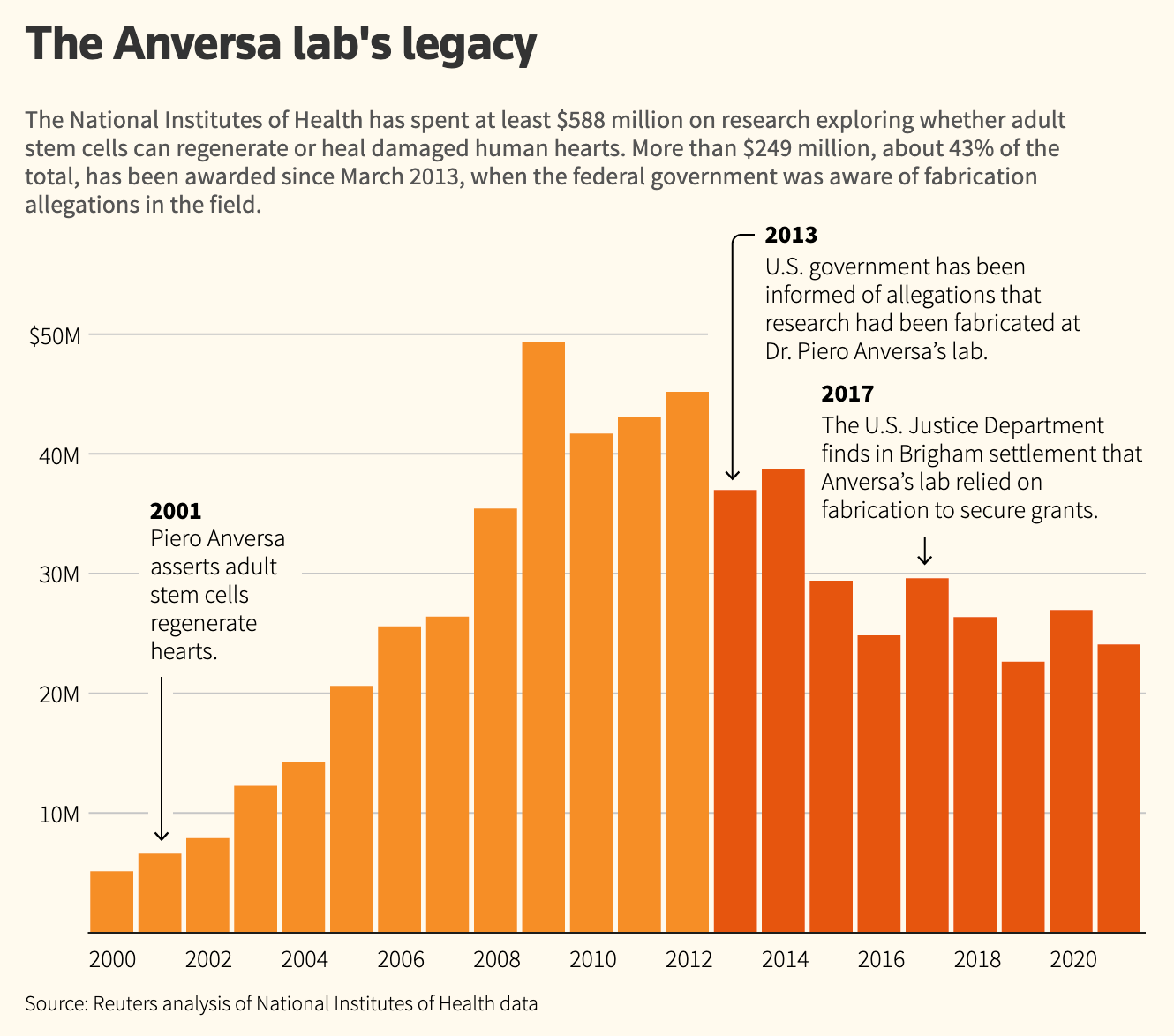
Reuters quotes Jeffery Molkentin, the director of molecular cardiovascular biology at Cincinnati Children’s Hospital:
Now that we know that adult stem cells do not regenerate the heart and that past work suggesting otherwise was false, why hasn’t this knowledge traversed its way through the medical and research systems, and why do such studies persist?
A significant number of heart patients, potentially impacted by the fraud, remained uninformed about the malfeasance as they made a decision between participating in trials or opting for conventional treatments. Reuters found that at least 5000 people were included in stem cell studies on hearts in the last 20 years.
I urge the reader to read the whole depressing report, which contains a paragraph that is especially pertinent to our discussion:
Anversa’s case shows how a dramatic claim of scientific discovery can gain credibility and attract grants, private investment and backing even from world-class medical institutions despite evidence that the underlying research is flawed or faked. Even after core work is discredited, millions may continue to be spent on a questionable hypothesis, distorting the overall direction of scientific inquiry, specialists in research malfeasance say.
It's important to recognize many of the issues I raise in this post are not exclusive to psychology or the social sciences. Since the incentives in all of academia are the same, many fields suffer from a surprising amount of outright fake and fraudulent studies. For some particularly depressing glimpses of fraud in biomedical research, the brave reader may pick from the following posts: Dana-Farberications at Harvard University, Memorial Sloan Kettering Paper Mill, and Fulda & Debatin: Reproducibility of Results in Medical and Biomedical Research. For mental health reasons, I advise not reading all of these articles in one sitting, especially not right after finishing this one.
Not Salvageable
I don’t think that academic psychology can be salvaged. Some of this critique has been around and ignored for at least 70 years. Even in cases where an effect has been widely discredited, it continues to be cited. For example, Kahneman mentions in his new book Noise that “If judges are hungry, they are tougher” referencing the famous study by Danziger et al. that presumably showed how susceptible judges are to hunger. The effect is fake: Dazinger and his colleagues simply overlooked the non-random scheduling of parole hearings.
However, everyone should have rejected the study without any additional analysis by simply looking at the effect size:
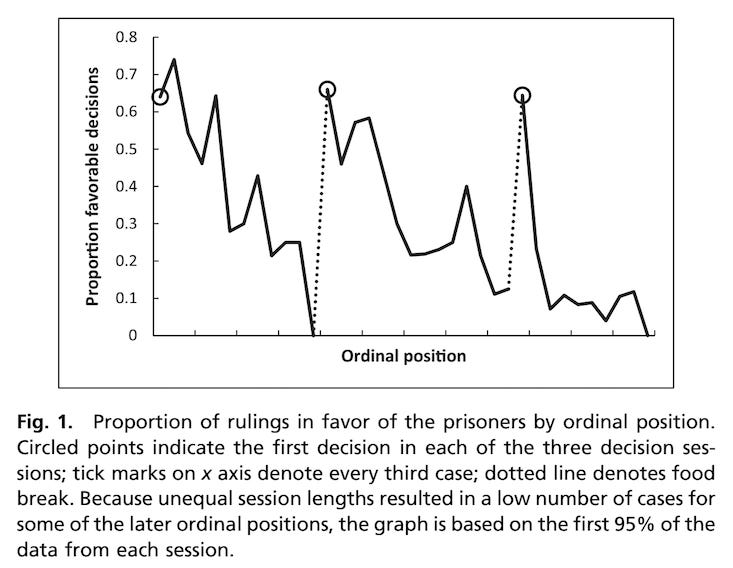
The study reported a drastic decline in favorable decisions, from 65% to nearly zero, over a session. This dramatic decline was attributed to the psychological effect of food. As Daniel Lakens correctly observes:
If hunger had an effect on our mental resources of this magnitude, our society would fall into minor chaos every day at 11:45 a.m.
The fact that this work has not only been accepted but is also cited in Kahneman's most recent book, should be enough to settle the question of whether academic psychology can be saved.
(Ego depletion is also fake but researchers whose careers depend on it are still trying to squeeze some blood out of this rock.)
With all of this in mind, it becomes apparent that at least 90% of papers in psychology fall into the category of Cargo Cult Science. Nobody seems to “lean over backwards” to expose flaws in their own paper ever. Instead, they obscure any flaws and attempt to exaggerate the magnitude of their findings as much as possible.
The tiny fraction of psychology research that might hold genuine scientific value goes unnoticed because it doesn't generate sensational headlines conducive to popular science books. (For the record, I’m not convinced that such a fraction exists.) For instance, a friend of mine recently mentioned Neo-Piagetian theories of cognitive development. While I haven’t looked deeply into this area, and it may well have its own shortcomings, it appears to represent a segment of psychology that could, a least in theory, offer valuable scientific explanations. This contrasts starkly with the explanationless accumulation of correlations, biases, and survey data, which contribute nothing to our understanding of human psychology but make up the majority of the famous “research.”
I acknowledge that this paints a rather bleak and disheartening picture of the current academic landscape. Those who have read some of my other posts that touch upon the same subject – The Problem is Not Plagiarism, but Cargo Cult Science, The Religion of Science And Its Consequences, A Skeptical Perspective on Quantum Computing, The Truth Will Cost You Dearly – know that I attribute the state of academia to the way the system is set up, which limits the possible avenues for improvement considerably. For the time being, growing independent science funding seems like a valuable step. While this won't solve the problem, it is likely part of the solution.